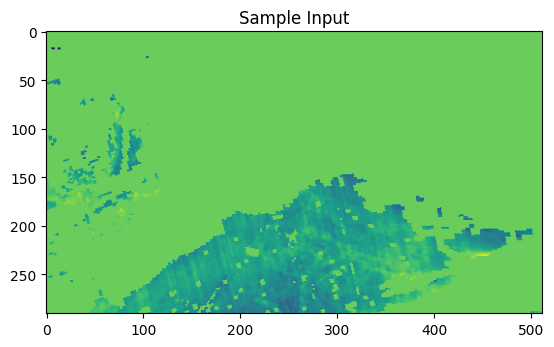
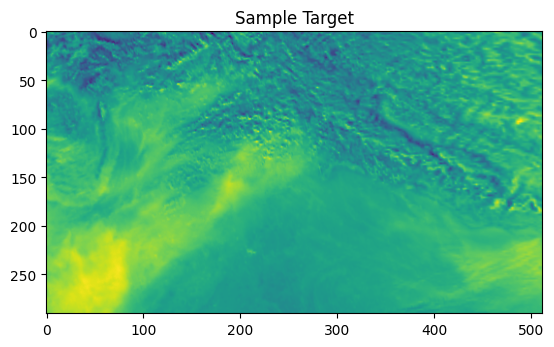
# Define the model with correct input shape = layers.Input(shape= (1 , X_data_clean.shape[2 ], X_data_clean.shape[3 ], X_data_clean.shape[4 ]))= layers.BatchNormalization()(inp)= layers.ConvLSTM2D(= 16 ,= (3 , 3 ),= "same" ,= True ,= "tanh" ,= "sigmoid" ,= "glorot_uniform" = layers.BatchNormalization()(x)= layers.ConvLSTM2D(= 32 ,= (3 , 3 ),= "same" ,= True ,= "tanh" ,= "sigmoid" ,= "glorot_uniform" = layers.BatchNormalization()(x)= layers.Conv3D(= 1 , kernel_size= (3 , 3 , 3 ), activation= "sigmoid" , padding= "same" = keras.models.Model(inp, x, name= "smogseer" )# Use a reduced learning rate and gradient clipping = keras.optimizers.Adam(learning_rate= 1e-5 , clipnorm= 1.0 )compile (= keras.losses.binary_crossentropy,= optimizer,= ['mean_squared_error' ]# Print the model summary # Data Generator Class class DataGenerator(Sequence):def __init__ (self , X_data, y_data, batch_size):self .X_data = X_dataself .y_data = y_dataself .batch_size = batch_sizeself .indices = np.arange(X_data.shape[0 ])def __len__ (self ):return int (np.ceil(len (self .indices) / self .batch_size))def __getitem__ (self , index):= self .indices[index * self .batch_size:(index + 1 ) * self .batch_size]= self .X_data[batch_indices]= self .y_data[batch_indices]return batch_X, batch_ydef on_epoch_end(self ):self .indices)= 1 = DataGenerator(X_train, y_train, batch_size)= DataGenerator(X_val, y_val, batch_size)# Define callbacks for monitoring and adjusting learning rate = [= 'val_loss' , factor= 0.1 , patience= 10 , verbose= 1 , min_lr= 1e-7 = 'val_loss' , patience= 15 , verbose= 1 , restore_best_weights= True = './logs' )# Train the model using data generators = model.fit(train_generator, epochs= 100 , validation_data= val_generator, callbacks= callbacks)# Save the model 'smogseer.keras' )
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ input_layer (InputLayer ) │ (None , 1 , 291 , 512 , 6 ) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ batch_normalization │ (None , 1 , 291 , 512 , 6 ) │ 24 │
│ (BatchNormalization ) │ │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv_lstm2d (ConvLSTM2D ) │ (None , 1 , 291 , 512 , │ 12,736 │
│ │ 16 ) │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ batch_normalization_1 │ (None , 1 , 291 , 512 , │ 64 │
│ (BatchNormalization ) │ 16 ) │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv_lstm2d_1 (ConvLSTM2D ) │ (None , 1 , 291 , 512 , │ 55,424 │
│ │ 32 ) │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ batch_normalization_2 │ (None , 1 , 291 , 512 , │ 128 │
│ (BatchNormalization ) │ 32 ) │ │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv3d (Conv3D ) │ (None , 1 , 291 , 512 , 1 ) │ 865 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 69,241 (270.47 KB)
Trainable params: 69,133 (270.05 KB)
Non-trainable params: 108 (432.00 B)
c:\Users\khant\Documents\smogseer\venv\lib\site-packages\keras\src\trainers\data_adapters\py_dataset_adapter.py:121: UserWarning: Your `PyDataset` class should call `super().__init__(**kwargs)` in its constructor. `**kwargs` can include `workers`, `use_multiprocessing`, `max_queue_size`. Do not pass these arguments to `fit()`, as they will be ignored.
self._warn_if_super_not_called()
292/292 ━━━━━━━━━━━━━━━━━━━━ 143s 472ms/step - loss: 0.7290 - mean_squared_error: 0.1448 - val_loss: 0.6891 - val_mean_squared_error: 0.1320 - learning_rate: 1.0000e-05
Epoch 2/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 469ms/step - loss: 0.7017 - mean_squared_error: 0.1329 - val_loss: 0.6959 - val_mean_squared_error: 0.1347 - learning_rate: 1.0000e-05
Epoch 3/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 466ms/step - loss: 0.6911 - mean_squared_error: 0.1275 - val_loss: 0.6945 - val_mean_squared_error: 0.1335 - learning_rate: 1.0000e-05
Epoch 4/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 474ms/step - loss: 0.6827 - mean_squared_error: 0.1240 - val_loss: 0.6839 - val_mean_squared_error: 0.1284 - learning_rate: 1.0000e-05
Epoch 5/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 466ms/step - loss: 0.6741 - mean_squared_error: 0.1198 - val_loss: 0.6764 - val_mean_squared_error: 0.1248 - learning_rate: 1.0000e-05
Epoch 6/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 141s 482ms/step - loss: 0.6639 - mean_squared_error: 0.1150 - val_loss: 0.6625 - val_mean_squared_error: 0.1180 - learning_rate: 1.0000e-05
Epoch 7/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 150s 513ms/step - loss: 0.6518 - mean_squared_error: 0.1083 - val_loss: 0.6491 - val_mean_squared_error: 0.1114 - learning_rate: 1.0000e-05
Epoch 8/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 153s 523ms/step - loss: 0.6380 - mean_squared_error: 0.1018 - val_loss: 0.6330 - val_mean_squared_error: 0.1035 - learning_rate: 1.0000e-05
Epoch 9/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 143s 488ms/step - loss: 0.6223 - mean_squared_error: 0.0940 - val_loss: 0.6140 - val_mean_squared_error: 0.0941 - learning_rate: 1.0000e-05
Epoch 10/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 474ms/step - loss: 0.6055 - mean_squared_error: 0.0856 - val_loss: 0.5990 - val_mean_squared_error: 0.0868 - learning_rate: 1.0000e-05
Epoch 11/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 474ms/step - loss: 0.5873 - mean_squared_error: 0.0776 - val_loss: 0.5783 - val_mean_squared_error: 0.0768 - learning_rate: 1.0000e-05
Epoch 12/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.5693 - mean_squared_error: 0.0687 - val_loss: 0.5591 - val_mean_squared_error: 0.0677 - learning_rate: 1.0000e-05
Epoch 13/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 473ms/step - loss: 0.5517 - mean_squared_error: 0.0597 - val_loss: 0.5410 - val_mean_squared_error: 0.0591 - learning_rate: 1.0000e-05
Epoch 14/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 145s 497ms/step - loss: 0.5337 - mean_squared_error: 0.0515 - val_loss: 0.5243 - val_mean_squared_error: 0.0514 - learning_rate: 1.0000e-05
Epoch 15/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 142s 488ms/step - loss: 0.5173 - mean_squared_error: 0.0436 - val_loss: 0.5077 - val_mean_squared_error: 0.0438 - learning_rate: 1.0000e-05
Epoch 16/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 145s 496ms/step - loss: 0.5011 - mean_squared_error: 0.0367 - val_loss: 0.4921 - val_mean_squared_error: 0.0369 - learning_rate: 1.0000e-05
Epoch 17/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 146s 501ms/step - loss: 0.4868 - mean_squared_error: 0.0304 - val_loss: 0.4785 - val_mean_squared_error: 0.0311 - learning_rate: 1.0000e-05
Epoch 18/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 142s 485ms/step - loss: 0.4738 - mean_squared_error: 0.0247 - val_loss: 0.4654 - val_mean_squared_error: 0.0256 - learning_rate: 1.0000e-05
Epoch 19/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4612 - mean_squared_error: 0.0201 - val_loss: 0.4515 - val_mean_squared_error: 0.0200 - learning_rate: 1.0000e-05
Epoch 20/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 473ms/step - loss: 0.4499 - mean_squared_error: 0.0160 - val_loss: 0.4439 - val_mean_squared_error: 0.0171 - learning_rate: 1.0000e-05
Epoch 21/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 469ms/step - loss: 0.4414 - mean_squared_error: 0.0124 - val_loss: 0.4351 - val_mean_squared_error: 0.0137 - learning_rate: 1.0000e-05
Epoch 22/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 469ms/step - loss: 0.4354 - mean_squared_error: 0.0095 - val_loss: 0.4283 - val_mean_squared_error: 0.0112 - learning_rate: 1.0000e-05
Epoch 23/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4290 - mean_squared_error: 0.0071 - val_loss: 0.4227 - val_mean_squared_error: 0.0093 - learning_rate: 1.0000e-05
Epoch 24/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 139s 477ms/step - loss: 0.4218 - mean_squared_error: 0.0056 - val_loss: 0.4174 - val_mean_squared_error: 0.0075 - learning_rate: 1.0000e-05
Epoch 25/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 466ms/step - loss: 0.4188 - mean_squared_error: 0.0041 - val_loss: 0.4146 - val_mean_squared_error: 0.0065 - learning_rate: 1.0000e-05
Epoch 26/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 467ms/step - loss: 0.4148 - mean_squared_error: 0.0032 - val_loss: 0.4108 - val_mean_squared_error: 0.0053 - learning_rate: 1.0000e-05
Epoch 27/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 145s 496ms/step - loss: 0.4136 - mean_squared_error: 0.0025 - val_loss: 0.4082 - val_mean_squared_error: 0.0044 - learning_rate: 1.0000e-05
Epoch 28/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 154s 527ms/step - loss: 0.4110 - mean_squared_error: 0.0019 - val_loss: 0.4063 - val_mean_squared_error: 0.0038 - learning_rate: 1.0000e-05
Epoch 29/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 142s 487ms/step - loss: 0.4096 - mean_squared_error: 0.0016 - val_loss: 0.4058 - val_mean_squared_error: 0.0037 - learning_rate: 1.0000e-05
Epoch 30/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 470ms/step - loss: 0.4096 - mean_squared_error: 0.0013 - val_loss: 0.4050 - val_mean_squared_error: 0.0034 - learning_rate: 1.0000e-05
Epoch 31/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 473ms/step - loss: 0.4102 - mean_squared_error: 0.0012 - val_loss: 0.4044 - val_mean_squared_error: 0.0033 - learning_rate: 1.0000e-05
Epoch 32/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 474ms/step - loss: 0.4090 - mean_squared_error: 0.0011 - val_loss: 0.4040 - val_mean_squared_error: 0.0031 - learning_rate: 1.0000e-05
Epoch 33/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4087 - mean_squared_error: 0.0010 - val_loss: 0.4033 - val_mean_squared_error: 0.0029 - learning_rate: 1.0000e-05
Epoch 34/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4079 - mean_squared_error: 0.0010 - val_loss: 0.4037 - val_mean_squared_error: 0.0030 - learning_rate: 1.0000e-05
Epoch 35/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 142s 485ms/step - loss: 0.4109 - mean_squared_error: 9.6707e-04 - val_loss: 0.4032 - val_mean_squared_error: 0.0029 - learning_rate: 1.0000e-05
Epoch 36/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 153s 525ms/step - loss: 0.4092 - mean_squared_error: 9.3389e-04 - val_loss: 0.4035 - val_mean_squared_error: 0.0030 - learning_rate: 1.0000e-05
Epoch 37/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 154s 529ms/step - loss: 0.4071 - mean_squared_error: 9.4938e-04 - val_loss: 0.4025 - val_mean_squared_error: 0.0027 - learning_rate: 1.0000e-05
Epoch 38/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 143s 490ms/step - loss: 0.4065 - mean_squared_error: 9.0768e-04 - val_loss: 0.4027 - val_mean_squared_error: 0.0027 - learning_rate: 1.0000e-05
Epoch 39/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 470ms/step - loss: 0.4091 - mean_squared_error: 8.5881e-04 - val_loss: 0.4029 - val_mean_squared_error: 0.0028 - learning_rate: 1.0000e-05
Epoch 40/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 471ms/step - loss: 0.4084 - mean_squared_error: 8.5700e-04 - val_loss: 0.4027 - val_mean_squared_error: 0.0027 - learning_rate: 1.0000e-05
Epoch 41/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4080 - mean_squared_error: 8.3285e-04 - val_loss: 0.4026 - val_mean_squared_error: 0.0028 - learning_rate: 1.0000e-05
Epoch 42/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4066 - mean_squared_error: 8.5810e-04 - val_loss: 0.4024 - val_mean_squared_error: 0.0027 - learning_rate: 1.0000e-05
Epoch 43/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 471ms/step - loss: 0.4102 - mean_squared_error: 8.3282e-04 - val_loss: 0.4024 - val_mean_squared_error: 0.0027 - learning_rate: 1.0000e-05
Epoch 44/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 143s 490ms/step - loss: 0.4078 - mean_squared_error: 7.6995e-04 - val_loss: 0.4025 - val_mean_squared_error: 0.0027 - learning_rate: 1.0000e-05
Epoch 45/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 150s 515ms/step - loss: 0.4082 - mean_squared_error: 7.7627e-04 - val_loss: 0.4023 - val_mean_squared_error: 0.0026 - learning_rate: 1.0000e-05
Epoch 46/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 148s 507ms/step - loss: 0.4092 - mean_squared_error: 7.8152e-04 - val_loss: 0.4020 - val_mean_squared_error: 0.0026 - learning_rate: 1.0000e-05
Epoch 47/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 144s 492ms/step - loss: 0.4082 - mean_squared_error: 7.3046e-04 - val_loss: 0.4020 - val_mean_squared_error: 0.0026 - learning_rate: 1.0000e-05
Epoch 48/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 469ms/step - loss: 0.4087 - mean_squared_error: 7.4382e-04 - val_loss: 0.4021 - val_mean_squared_error: 0.0026 - learning_rate: 1.0000e-05
Epoch 49/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 470ms/step - loss: 0.4066 - mean_squared_error: 7.5448e-04 - val_loss: 0.4021 - val_mean_squared_error: 0.0026 - learning_rate: 1.0000e-05
Epoch 50/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 470ms/step - loss: 0.4072 - mean_squared_error: 7.7316e-04 - val_loss: 0.4020 - val_mean_squared_error: 0.0026 - learning_rate: 1.0000e-05
Epoch 51/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 473ms/step - loss: 0.4084 - mean_squared_error: 7.0784e-04 - val_loss: 0.4020 - val_mean_squared_error: 0.0025 - learning_rate: 1.0000e-05
Epoch 52/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 471ms/step - loss: 0.4087 - mean_squared_error: 7.3632e-04 - val_loss: 0.4020 - val_mean_squared_error: 0.0026 - learning_rate: 1.0000e-05
Epoch 53/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 142s 486ms/step - loss: 0.4063 - mean_squared_error: 7.1279e-04 - val_loss: 0.4020 - val_mean_squared_error: 0.0026 - learning_rate: 1.0000e-05
Epoch 54/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 145s 497ms/step - loss: 0.4082 - mean_squared_error: 6.9338e-04 - val_loss: 0.4017 - val_mean_squared_error: 0.0025 - learning_rate: 1.0000e-05
Epoch 55/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 149s 511ms/step - loss: 0.4068 - mean_squared_error: 6.9151e-04 - val_loss: 0.4017 - val_mean_squared_error: 0.0025 - learning_rate: 1.0000e-05
Epoch 56/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 141s 484ms/step - loss: 0.4070 - mean_squared_error: 6.7310e-04 - val_loss: 0.4021 - val_mean_squared_error: 0.0026 - learning_rate: 1.0000e-05
Epoch 57/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 470ms/step - loss: 0.4069 - mean_squared_error: 6.8701e-04 - val_loss: 0.4019 - val_mean_squared_error: 0.0025 - learning_rate: 1.0000e-05
Epoch 58/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4067 - mean_squared_error: 7.1130e-04 - val_loss: 0.4019 - val_mean_squared_error: 0.0025 - learning_rate: 1.0000e-05
Epoch 59/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 469ms/step - loss: 0.4079 - mean_squared_error: 6.7344e-04 - val_loss: 0.4021 - val_mean_squared_error: 0.0026 - learning_rate: 1.0000e-05
Epoch 60/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 470ms/step - loss: 0.4085 - mean_squared_error: 6.8823e-04 - val_loss: 0.4016 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 61/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4087 - mean_squared_error: 6.4379e-04 - val_loss: 0.4018 - val_mean_squared_error: 0.0025 - learning_rate: 1.0000e-05
Epoch 62/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 139s 476ms/step - loss: 0.4060 - mean_squared_error: 6.5046e-04 - val_loss: 0.4017 - val_mean_squared_error: 0.0025 - learning_rate: 1.0000e-05
Epoch 63/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4051 - mean_squared_error: 6.1816e-04 - val_loss: 0.4016 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 64/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 465ms/step - loss: 0.4089 - mean_squared_error: 6.1312e-04 - val_loss: 0.4016 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 65/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 142s 486ms/step - loss: 0.4068 - mean_squared_error: 6.4825e-04 - val_loss: 0.4014 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 66/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 151s 517ms/step - loss: 0.4057 - mean_squared_error: 6.1512e-04 - val_loss: 0.4015 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 67/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 155s 532ms/step - loss: 0.4075 - mean_squared_error: 6.2446e-04 - val_loss: 0.4015 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 68/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 465ms/step - loss: 0.4074 - mean_squared_error: 5.9204e-04 - val_loss: 0.4014 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 69/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 466ms/step - loss: 0.4068 - mean_squared_error: 6.0754e-04 - val_loss: 0.4015 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 70/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4056 - mean_squared_error: 6.0360e-04 - val_loss: 0.4023 - val_mean_squared_error: 0.0027 - learning_rate: 1.0000e-05
Epoch 71/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 139s 475ms/step - loss: 0.4064 - mean_squared_error: 6.0216e-04 - val_loss: 0.4016 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 72/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 467ms/step - loss: 0.4074 - mean_squared_error: 5.6818e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-05
Epoch 73/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 469ms/step - loss: 0.4077 - mean_squared_error: 5.8116e-04 - val_loss: 0.4015 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 74/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 146s 500ms/step - loss: 0.4056 - mean_squared_error: 5.9187e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-05
Epoch 75/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 150s 515ms/step - loss: 0.4066 - mean_squared_error: 5.6511e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 76/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 147s 504ms/step - loss: 0.4078 - mean_squared_error: 5.5301e-04 - val_loss: 0.4015 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 77/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 472ms/step - loss: 0.4076 - mean_squared_error: 5.5795e-04 - val_loss: 0.4017 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 78/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 470ms/step - loss: 0.4045 - mean_squared_error: 5.5711e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-05
Epoch 79/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 465ms/step - loss: 0.4070 - mean_squared_error: 5.5179e-04 - val_loss: 0.4016 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 80/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 465ms/step - loss: 0.4070 - mean_squared_error: 5.6309e-04 - val_loss: 0.4015 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 81/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 466ms/step - loss: 0.4083 - mean_squared_error: 5.5748e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-05
Epoch 82/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 140s 480ms/step - loss: 0.4079 - mean_squared_error: 5.1798e-04 - val_loss: 0.4014 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 83/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 144s 494ms/step - loss: 0.4055 - mean_squared_error: 5.5006e-04 - val_loss: 0.4015 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 84/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 0s 508ms/step - loss: 0.4075 - mean_squared_error: 5.0081e-04
Epoch 84: ReduceLROnPlateau reducing learning rate to 9.999999747378752e-07.
292/292 ━━━━━━━━━━━━━━━━━━━━ 150s 513ms/step - loss: 0.4075 - mean_squared_error: 5.0092e-04 - val_loss: 0.4016 - val_mean_squared_error: 0.0024 - learning_rate: 1.0000e-05
Epoch 85/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 144s 493ms/step - loss: 0.4071 - mean_squared_error: 5.4880e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 86/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 474ms/step - loss: 0.4065 - mean_squared_error: 5.2907e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 87/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 466ms/step - loss: 0.4068 - mean_squared_error: 5.1186e-04 - val_loss: 0.4011 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 88/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 465ms/step - loss: 0.4057 - mean_squared_error: 5.3199e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 89/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 136s 466ms/step - loss: 0.4072 - mean_squared_error: 5.4235e-04 - val_loss: 0.4011 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 90/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 469ms/step - loss: 0.4053 - mean_squared_error: 5.0030e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 91/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 140s 480ms/step - loss: 0.4060 - mean_squared_error: 5.1027e-04 - val_loss: 0.4011 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 92/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 144s 493ms/step - loss: 0.4064 - mean_squared_error: 5.2571e-04 - val_loss: 0.4011 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 93/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 144s 493ms/step - loss: 0.4065 - mean_squared_error: 5.3916e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 94/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 145s 497ms/step - loss: 0.4077 - mean_squared_error: 5.1107e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 95/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 143s 490ms/step - loss: 0.4085 - mean_squared_error: 5.0312e-04 - val_loss: 0.4013 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 96/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 137s 470ms/step - loss: 0.4053 - mean_squared_error: 4.9508e-04 - val_loss: 0.4011 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 97/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 0s 467ms/step - loss: 0.4073 - mean_squared_error: 4.9562e-04
Epoch 97: ReduceLROnPlateau reducing learning rate to 1e-07.
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 474ms/step - loss: 0.4073 - mean_squared_error: 4.9570e-04 - val_loss: 0.4010 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-06
Epoch 98/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 139s 474ms/step - loss: 0.4071 - mean_squared_error: 5.2952e-04 - val_loss: 0.4010 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-07
Epoch 99/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 474ms/step - loss: 0.4060 - mean_squared_error: 4.8378e-04 - val_loss: 0.4012 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-07
Epoch 100/100
292/292 ━━━━━━━━━━━━━━━━━━━━ 138s 474ms/step - loss: 0.4075 - mean_squared_error: 5.2382e-04 - val_loss: 0.4011 - val_mean_squared_error: 0.0023 - learning_rate: 1.0000e-07
Restoring model weights from the end of the best epoch: 97.